Why Phishing?
In the last five years or so, we have become closely acquainted with Security Operation Center (SOC) teams that use Cortex XSOAR. One of the first things we learned was that reviewing potential phishing incidents consumes a significant portion of time in many SOCs. The volume of such incidents is normally high, and they usually require a manual review step. Many of the suspected phishing incidents turn out to be false positives.
When we analyzed what most analysts do to investigate a potential phishing attack, we realized that this is a classic challenge that machine learning (ML) can solve. The result? A phishing e-mail classifier aimed to help organizations detect malicious phishing emails with a high degree of accuracy.
Here are some of the considerations we took into account to make the model work for as many SOCs as possible:
- When investigating phishing incidents, SOC teams use different tools and services that provide enriched data on indicators found within the emails (IP addresses, attachments, URLs, and so on) to see if any proof of malice exists. The phishing classifier adds additional perspective as a text classifier, which means that it’s trained based on the text of the email. By learning word patterns that correspond with phishing and non-phishing emails, it can predict whether a given new email is phishing or not. Therefore, it can supplement existing tools which often do not take the email text into account.
- The training of the phishing classifier is done using historical emails identified and classified as malicious by the organization. Phishing attempts might differ significantly from one organization to another. Therefore, training a classifier based on your own emails has the potential to yield a classifier which is adjusted to your typical phishing emails and therefore a lot more accurate than a generic solution.
- The training of the phishing classifier is done within your environment. We are aware that phishing incidents contain sensitive data. Therefore, we designed the phishing classifier as an integrated part of Cortex XSOAR so that your emails do not need to be sent to a third party. The pre-processing of the emails and the training of the phishing classifier are all done in Cortex XSOAR and do not require any export of emails.
- You can train a phishing classifier with a relatively small number of incidents. The phishing classifier is a deep learning model. It achieves a model with relatively high precision, even if it’s trained on a small number of incidents.
- It’s possible to use the phishing classifier in multiple ways. Customers can choose to present the classifier’s output to human SOC analysts as an additional parameter to consider. Another option is to prioritize the incidents which the classifier predicts as phishing, within a high confidence. The final option is full automation, where incidents can be closed automatically, or emails searched and destroyed based on the classifier’s prediction. The decision of how to use the model is taken based on the performance of the classifier, and based on where it can be of most benefit to the SOC team. We will return to this point later in this blog.
How to Train your Phishing Email Classifier
Usually ML projects are complicated, and require preliminary research, data collection, pre-processing, training a model, and evaluation stages. Just like the training of dragons, it is very rare that a product allows customers to train their own machine. But since we believe that the classifier will give the highest benefit when trained locally, we invested a lot in making sure that customers can easily perform the training, and the entire process is done within the Cortex XSOAR interface via an easy to understand UI.
The training can be set using the designated “ML Models” page in Cortex XSOAR.
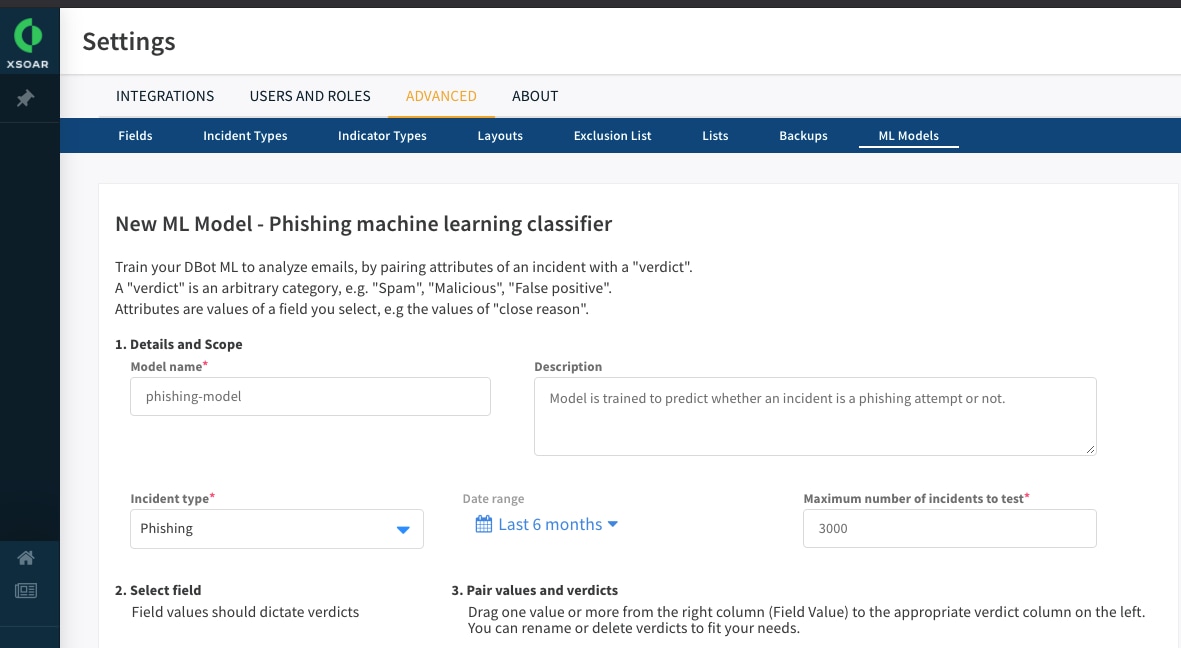
ML Model - Configuring Settings
We start by configuring the relevant setting for the training which includes defining the model’s name and its description, setting the training scope and which incident type will be used for training, the date range, and the number of incidents to be included in the training.

ML Model - define model tasks
For the next stage, we define the model’s task, in other words, the target variable which we want the model to learn to predict. First, we’ll choose the incident field where the incident classification or close reason is stated. In our example, the classification value of phishing incidents is stored in a field called “Email Classification”. Next, we decide which classification values will participate in the training and how. In the attached example, we want the model to learn to predict whether the incident is a phishing attempt or not. Therefore, we define two verdicts, which are groups of classification value: the first verdict is “Non-Phishing”, which is composed of incidents where the “Email Classification” value was “legit” or “spam”. The second verdict is “Phishing”, and it’s composed of incidents where the “Email Classification” value was “Phishing”. Two incidents where the “Email Classification” were “internal phishing test” and “unresolved” are left aside from training.
This mechanism offers great flexibility for training a model: you can merge existing classification values if needed, and remove certain classification values from training. This enables you to have as many classification values as you want, so your investigation process is not forced to fit the ML model.
How well is your Email Classifier learning to phish?
Once the model has been trained successfully, the next step is to evaluate it. The evaluation aims to quantify how many of the predictions of the model are correct. This is an important step when deciding how to use the model. Let’s assume that we’d like to perform an action for incidents which were predicted by the model as phishing, such as setting a higher severity. How many of these incidents will turn out to be malicious? How many are expected to be falsely predicted as phishing?
Due to the importance of this stage, an extensive evaluation of the model is performed upon training. By chronologically splitting the incidents into training and test sets, we simulate a production environment for the model, and test it using incidents which were not processed during the training. The result of this evaluation is a detailed report, which was designed to help both users who don’t have a former experience with ML projects, and ones who are familiar with ML terminology.

Phishing Model Confidence Level Threshold Requirements
The basic output of the evaluation process includes the precision of the model for each class (number at the top-right corner of the image), and a suggested confidence threshold. In brief, this serves as a recommendation on how to apply the model, in order to guarantee a certain degree of precision over all classes.
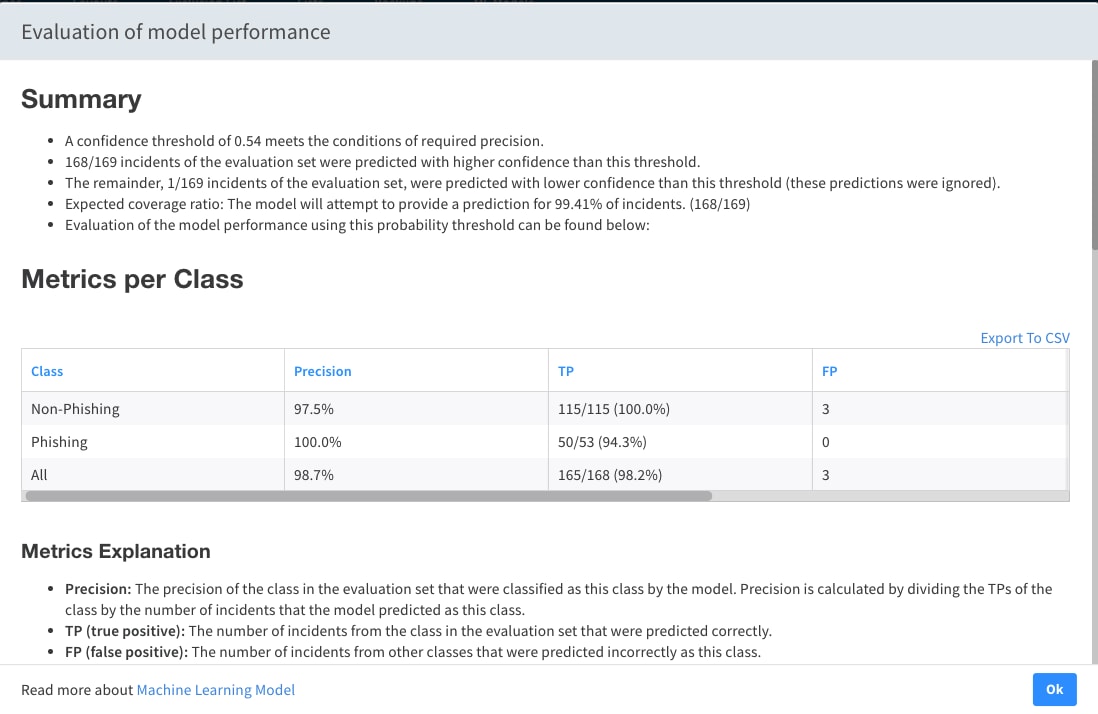
Sample Phishing Model Results
This detailed evaluation enables you to get a sense of how the model should perform from different aspects, to better understand the expected implications of applying it in a certain way.

Phishing Model Performance Prediction
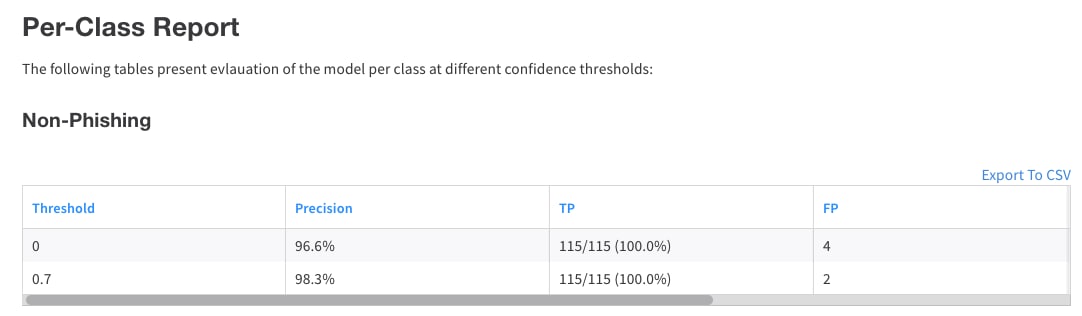
Sample Report Based on Different Confidence Thresholds
Putting the Phishing Email Classifier to work
Finally, it’s possible to involve the model’s predictions in various ways in the investigation process. You can display the model’s output as part of the phishing incident layout. That way, the analyst may see the predicted classification, the confidence of the model in its prediction, and extracted words from the email that were classified as “negative” or “positive”. Positive words are words in the email which led the model to predict the way it did. Negative words are words in the email which discouraged the model from making the prediction it made. These words often help the analysts to focus on important parts of the mail.

Automatic Actions Based on Model Predictions
Besides that, it’s also possible to make some automatic actions based on the model’s predictions. For instance, it’s possible to set higher severity to incidents which were predicted as phishing with high confidence, or even close incidents automatically or start a response procedure in such cases. This depends a lot on the organization’s needs, and the evaluation of the model as described above.
Summary
Cortex XSOAR enables users to leverage ML effectively in the investigation process of phishing incidents. In a couple short steps, users can configure the ML model training, get a detailed analysis of the results, and receive a recommendation for how to use it in production. It is yet another step in your SOC automation journey to eliminate unnecessary manual work. To paraphrase a well known saying, why deal with phish every day, when you can teach a bot to phish on your behalf for a lifetime?
Don't have Cortex XSOAR? Download our free Community Edition today!